If you haven’t done so by now, here is your chance to sign up to a free full day of SQL Server training. The last couple of years (read my recaps here and here) the event has attracted around 200 curious sql server developer/admin/bi/adhoc professionals not only from around the country, but also from countries around Europe. Your chance to mingle with your peers.
This years schedule consists of eight categories spread across five tracks. In total there will be technical 30 sessions plus sessions delivered by sponsors during the lunch break.
Apart from the native speakers, the event will host veteran International speakers again this year. So, hurry up, sign up before it’s too late!
This is my eighth post in a series of entry-level posts, as suggested by Tim Ford (b|l|t) in this challenge.
I have not set any scope for the topics of my, at least, twelve (12) posts in this blog category of mine, but I can assure, it’ll be focused on SQL Server stuff. This time, it’s a little trick on how to make life easier for SQL Server on an Azure Virtual Machine. This tip applies to standard on-premises setups as well, although it’s not always as easy as running a PowerShell script to magically conjure a bunch of disks, on your own servers.
Prerequisites
In order to leverage this tip, you will need an Azure VM (or an on-premises server, where you can add disks) and some administrative permissions.
Things to do in Azure
First of all, you need to add the Data Disks to you Virtual Machine. This can be done in two ways; (1) You can do this through the Portal. Select the VM you want to work with, click All Settings->Disks->Attach New.
This will bring you to the final dialog, where you punch in the specifics for your new disk.
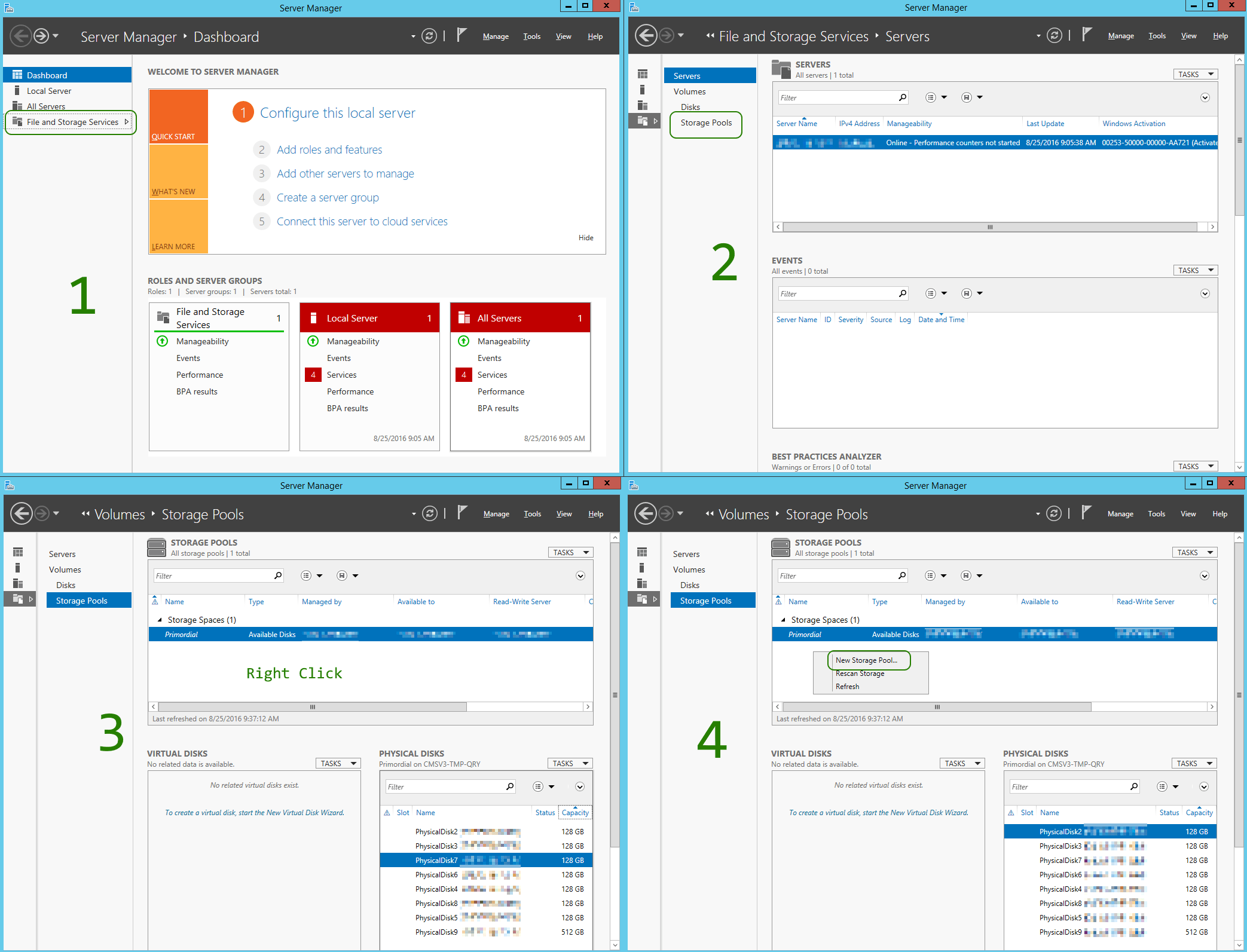
Once the disks have been attached to the VM, it’s time to do some magic in Windows. Mind you, a long series of screenshots. First, you’ll have to create a Storage Pool, next configure a Virtual Disk and finally a Volume (Disk).
It all begins with in the Server Manager, where this illustration should take you through the steps to create a Storage Pool:
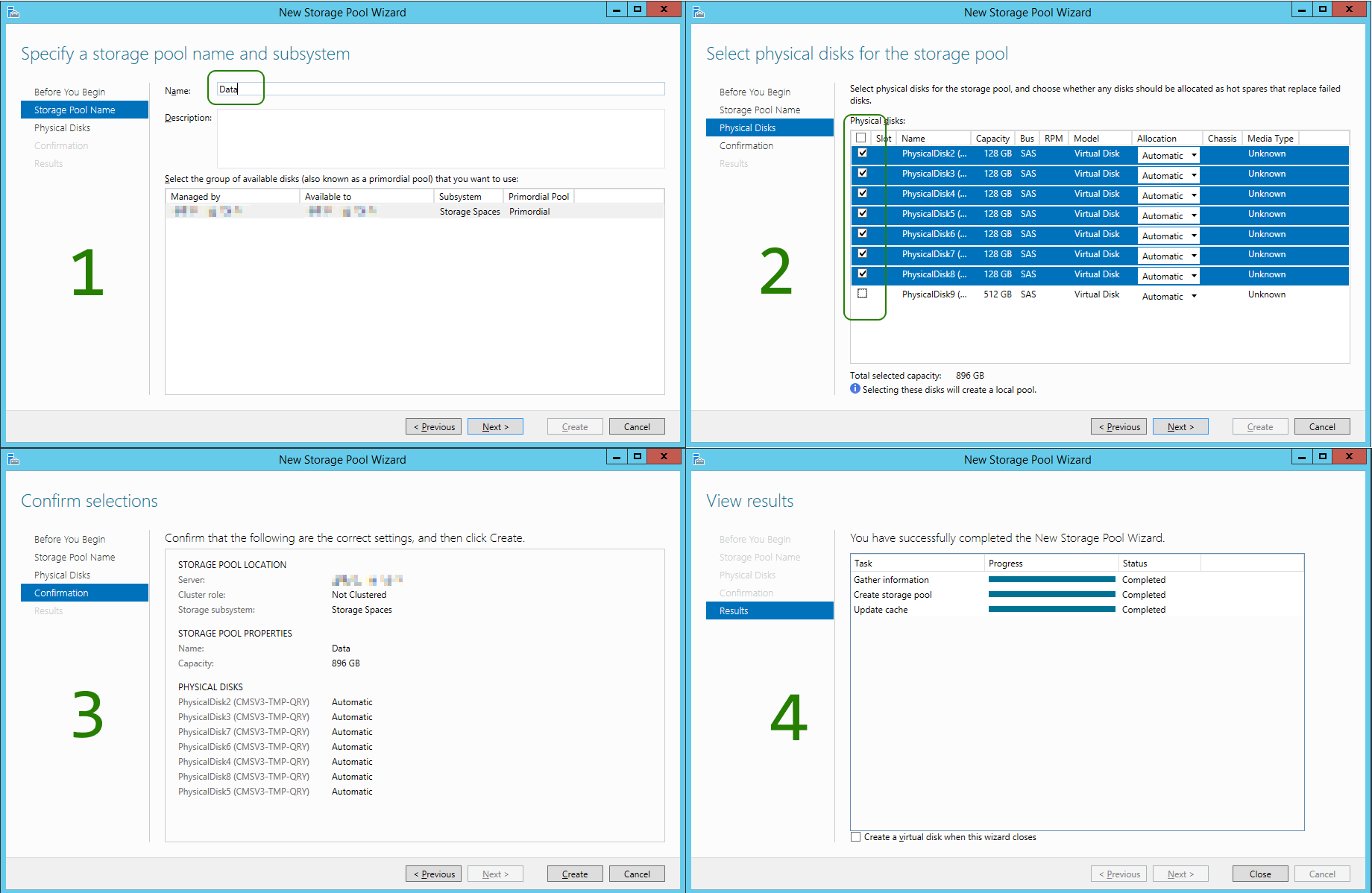
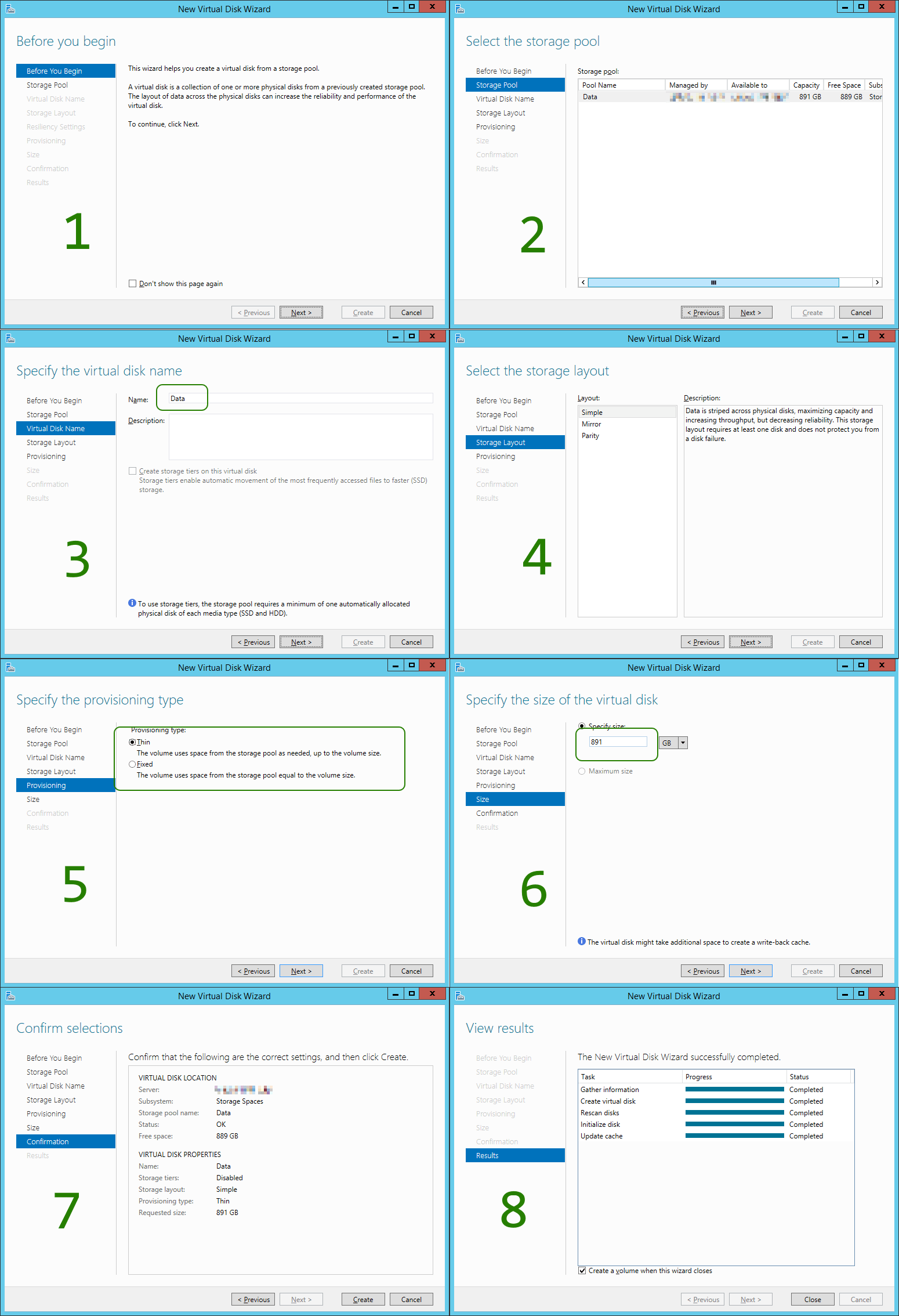
Once the Storage Pool is created, you head on to create the Virtual Disk:
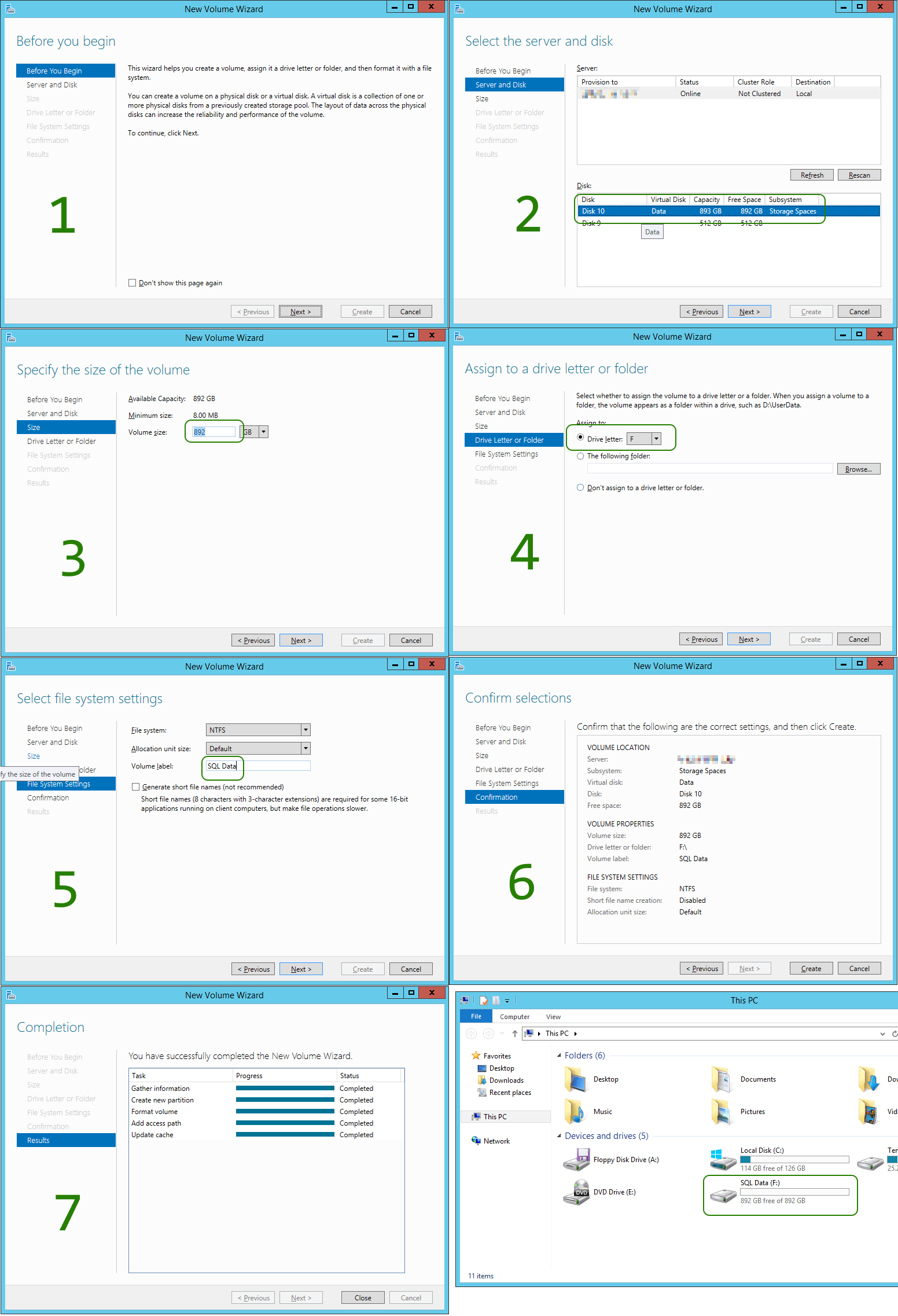
Finally you need to create a new Volume:
Benefits
The obvious benefit is throughput. The more disks you add to your stripe, the more theoretical throughput you’ll get. As an example, is ran a very quick test, using CrystalDiskMark
Beware: Do not use the installer, as it contains adware. Get the portable edition (.zip).
As displayed in above screen shots, the single Azure Standard Storage VHD gives you (as promised) about 500 IOPS. Striping eight (8) of those, will roughly give you eight (8) times the IOPS, but not same magnitude of [MB/s] apparently. Still, the setup is better off, after, rather than before!
Do mind, that there are three levels of storage performance; P10, P20 and P30. For more information, read this.
My session will be evolving around Azure IoT Hub, a Raspberry Pi3 device running the latest Windows 10 Core operating system. So if you want to know more about the options for Internet of Things in Azure.
If you are in the neighborhood, you should definitely check out this single day, _free_(!), event – all about SQL Server. There are a number of great sessions, and as usual, you will find it hard to build your own schedule; Deciding which sessions to attend, is always a task of picking only one session out of several, for the same time slot. This event is no different.
You should also look into the pre-con offered for this event; Performance Tuning w/ Uwe Ricken (b|l|t).
Last week I left home, bound for Dublin, to attend and speak at the SQLSaturday event organized by Bob Duffy (b|l|t), Carmel Gunn (b|l|t), Ben Watt (l|t), Dan Galavan (b|l|t) and many others.
I arrived in Dublin on Friday, getting settled in at the hotel, then took a quick peek at the venue, which was right on the back of the Hotel.
National College of Ireland
Friday night, all speakers were invited to attend a dinner on Quay 16, which turned out to be a smashing meal and really awesome company. If you ever get the chance of sitting at the same table as Buck Woody (b|l|t), you’re in for a treat.
Saturday
Rise n’ Shine, up early, to attend the first session of the Day, by Matt Masson (b|l|t). Except, Matt hat lost his voice halfway through his pre-con on Friday, needless to say, his sessions were cancelled. So I began the Day with a tour of the exhibitors and got a chance to talk to some of them. Next I went to attend the key note by Mark Souza (l|t) – What an amazing story-teller! After that, it feels like: It’s Just Faster… It just is…
During the next session, I went to the speakers room, to prepare for my own presentation. I had been selected to deliver a Lightning Talk on Custom Assemblies in Analysis Services. A topic I have written a couple of blog posts on, here and here. My presentation went well, even though only a few hands came up to the question on who was working with BI and SSAS. I was sharing session with Ben Watt (l|t), Andre Melancia (b|l|t) and Andrew Pruski (b|l|t), who all delivered excellent talks on Power BI, Certifications and Partitioning (T-SQL).
When the session was over, I had plenty of time since lunch was up next, followed by sponsor sessions – I skipped those, to take a break and talk with lots of people who wanted to chat about SQL Server 2016.
Next up, for me, was Rob Sewell (b|l|t) – I hadn’t had a chance before to see his PowerShell expertise unfold, so I grabbed the chance while it presented itself. Rob shared a lot of best practice and good advise. If you get the chance, attend his session – PowerShell is here to stay!
Final session of the Day, I selected to get an introduction to R in SQL Server 2016 by Marcin Szeliga (b|l|t). This session was also live streamed on Channel9, where you can still see it, for free, along with a selection of session from #SqlSat501.
Raffle time!
SqlSat501 Raffle Time
After finding the lucky winners, we all headed out in a court yard for some BBQ and beverages. A Perfect ending to a long day.
Sunday
Sunday was my day off, and I decided, based on numerous recommendations, to head out for the Guinness Storehouse. It was a good walk from the Hotel to the factory, and I didn’t mind the light rain on the way, but the view from the top floor was maybe not the one that goes into commercials. Still I think it was a nice trip and some great information about the beer, craftsmanship and history.
Et billede slået op af Jens Vestergaard (@jens_vestergaard) den
Dublin is full of all kinds of wonderful sculptures, old as new and I was fortunate enough to pass by a lot of it on my tour through the city. City centre was currently undergoing heavy rebuild, as I understood the tram was to be rediscovered – I wish that would happen in Copenhagen as well.
The Linesman
Leaving from Quay 16 this stunning view was presented.
Samuel Beckett Bridge by Night
In the afternoon, I was bound for home, wife and kids. I did get to shop some gifts for them, a genuine rugby, a rugby shirt and some other Irish treats.
I really enjoyed my stay in Dublin, and cannot thank Bob, Carmen, Ben, Dan and the rest of the team enough for giving me the opportunity to speak at their event. I hope to be back!
This is my seventh post in a series of entry-level posts, as suggested by Tim Ford (b|l|t) in this challenge.
I have not set any scope for the topics of my, at least, twelve (12) posts in this blog category of mine, but I can assure, it’ll be focused on SQL Server stuff. This time, it’s a little trick on how to execute DAX via a SQL Server Management Studio [SSMS] MDX Query.
In our current setup, we have both Reporting Services [SSRS] and PowerView Dashboards connecting to our underlying SQL Server Analysis Services [SSAS] cubes. And as we are constantly monitoring the servers, logging which queries are executed, we can tell which ones candidate for optimization. Now, with PowerView Dashboards we do not have the ability to change the actual DAX that gets send to the server. But we can execute the DAX, and trace whether aggregates are missing or if partitioning would be applicable.
Since we have the individual query, it would be nice to be able to execute these manually through SSMS with a SQL Trace running. Admitted, I am a Trace fan 🙂
This is actually possible, with only a little tweak.
In order to execute DAX on a SSAS Multidimensional cube, the Cube property of the connection string needs to be assigned. Here is how to do that.
Open a new MDX Query
You will be prompted for server, but before you assign any of that, hit the ‘Options’ button:
One of the properties available in the connection string is Cube. See full reference of connection string properties here. Select the third tab; Additional Connection Parameters, and assign the cube you want to query.
Write your DAX query, in the MDX query window
and execute it to see the results.
At the time of writing, not all of the queries we are logging are directly executable via this tweak, but we manage to get the long running ones going – which gives us enough insights to potentially fix or at least improve the query execution times.



 As displayed in above screen shots, the single Azure Standard Storage VHD gives you (as promised) about 500 IOPS. Striping eight (8) of those, will roughly give you eight (8) times the IOPS, but not same magnitude of [MB/s] apparently. Still, the setup is better off, after, rather than before!
As displayed in above screen shots, the single Azure Standard Storage VHD gives you (as promised) about 500 IOPS. Striping eight (8) of those, will roughly give you eight (8) times the IOPS, but not same magnitude of [MB/s] apparently. Still, the setup is better off, after, rather than before!



 You will be prompted for server, but before you assign any of that, hit the ‘Options’ button:
You will be prompted for server, but before you assign any of that, hit the ‘Options’ button: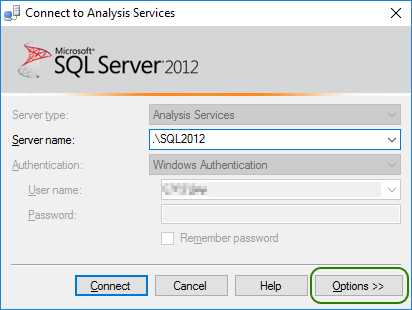


 At the time of writing, not all of the queries we are logging are directly executable via this tweak, but we manage to get the long running ones going – which gives us enough insights to potentially fix or at least improve the query execution times.
At the time of writing, not all of the queries we are logging are directly executable via this tweak, but we manage to get the long running ones going – which gives us enough insights to potentially fix or at least improve the query execution times.